
All Problems
14 problems1
Invert Binary Tree
You are given the root of a binary tree `root`. Invert the binary tree and return its root.
**Example 1:**
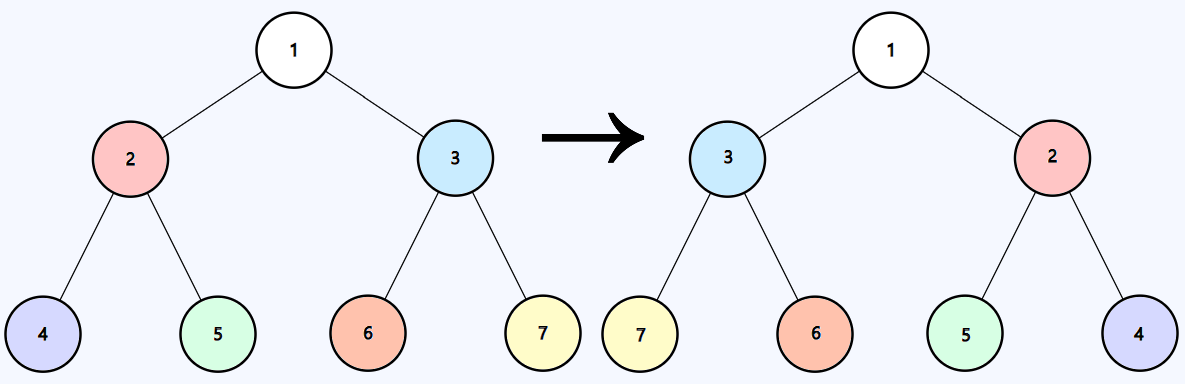
```java
Input: root = [1,2,3,4,5,6,7]
Output: [1,3,2,7,6,5,4]
```
**Example 2:**
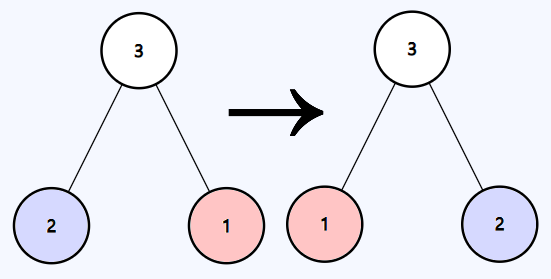
```java
Input: root = [3,2,1]
Output: [3,1,2]
```
**Example 3:**
```java
Input: root = []
Output: []
```
**Constraints:**
* `0 <= The number of nodes in the tree <= 100`.
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
From the diagram, you can see that the left and right children of every node in the tree are swapped. Can you think of a way to achieve this recursively? Maybe an algorithm that is helpful to traverse the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm. At each node, we swap its left and right children by swapping their pointers. This inverts the current node, but every node in the tree also needs to be inverted. To achieve this, we recursively visit the left and right children and perform the same operation. If the current node is <code>null</code>, we simply return.
</p>
</details>
Easy
Not Attempted
Video
2
Maximum Depth of Binary Tree
Given the `root` of a binary tree, return its **depth**.
The **depth** of a binary tree is defined as the number of nodes along the longest path from the root node down to the farthest leaf node.
**Example 1:**

```java
Input: root = [1,2,3,null,null,4]
Output: 3
```
**Example 2:**
```java
Input: root = []
Output: 0
```
**Constraints:**
* `0 <= The number of nodes in the tree <= 100`.
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
From the definition of binary tree's maximum depth, Can you think of a way to achieve this recursively? Maybe you should consider the max depth of the subtrees first before computing the maxdepth at the root.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We use the Depth First Search (DFS) algorithm to find the maximum depth of a binary tree, starting from the <code>root</code>. For the subtrees rooted at the <code>left</code> and <code>right</code> children of the <code>root</code> node, we calculate their maximum depths recursively going through <code>left</code> and <code>right</code> subtrees. We return <code>1 + max(leftDepth, rightDepth)</code>. Why?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
The <code>+1</code> accounts for the current node, as it contributes to the current depth in the recursion call. We pass the maximum depth from the current node's left and right subtrees to its parent because the current maximum depth determines the longest path from the parent to a leaf node through this subtree.
</p>
</details>
Easy
Not Attempted
Video
3
Diameter of Binary Tree
The **diameter** of a binary tree is defined as the **length** of the longest path between *any two nodes within the tree*. The path does not necessarily have to pass through the root.
The **length** of a path between two nodes in a binary tree is the number of edges between the nodes. Note that the path can *not* include the same node twice.
Given the root of a binary tree `root`, return the **diameter** of the tree.
**Example 1:**
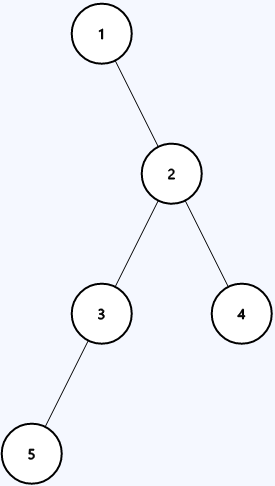
```java
Input: root = [1,null,2,3,4,5]
Output: 3
```
Explanation: 3 is the length of the path `[1,2,3,5]` or `[5,3,2,4]`.
**Example 2:**
```java
Input: root = [1,2,3]
Output: 2
```
**Constraints:**
* `1 <= number of nodes in the tree <= 100`
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
The diameter of a binary tree is the maximum among the sums of the left height and right height of the nodes in the tree. Why?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
Because the diameter of a binary tree is defined as the longest path between any two nodes in the tree. The path may or may not pass through the root. For any given node, the longest path that passes through it is the sum of the height of its left subtree and the height of its right subtree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
A brute force solution would be to go through every node in the tree and compute its left height and right height, returning the maximum diameter found. This would be an <code>O(n^2)</code> solution. Can you think of a better way? Maybe we can compute the diameter as we calculate the height of the tree? Think about what information you need from each subtree during a single traversal.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We can use the Depth First Search (DFS) algorithm to calculate the height of the tree. At each node, the subtrees return their respective heights (leftHeight and rightHeight). Then we calculate the diameter at that node as <code>d = leftHeight + rightHeight</code>. We use a global variable to update the maximum diameter as needed during the traversal.
</p>
</details>
Easy
Not Attempted
Video
4
Balanced Binary Tree
Given a binary tree, return `true` if it is **height-balanced** and `false` otherwise.
A **height-balanced** binary tree is defined as a binary tree in which the left and right subtrees of every node differ in height by no more than 1.
**Example 1:**
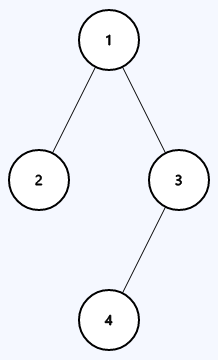
```java
Input: root = [1,2,3,null,null,4]
Output: true
```
**Example 2:**
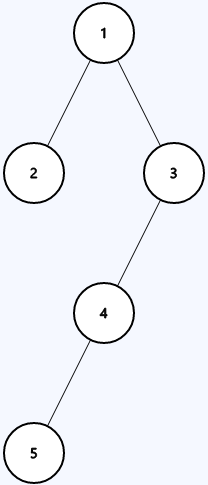
```java
Input: root = [1,2,3,null,null,4,null,5]
Output: false
```
**Example 3:**
```java
Input: root = []
Output: true
```
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-1000 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve traversing every node and checking whether the tree rooted at each node is balanced by computing the heights of its left and right subtrees. This approach would result in an <code>O(n^2)</code> solution. Can you think of a more efficient way? Perhaps you could avoid repeatedly computing the heights for every node by determining balance and height in a single traversal.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to compute the heights at each node. While calculating the heights of the left and right subtrees, we also check if the tree rooted at the current node is balanced. If <code>leftHeight - rightHeight > 1</code>, we update a global variable, such as <code>isBalanced = False</code>. After traversing all the nodes, the value of <code>isBalanced</code> indicates whether the entire tree is balanced or not.
</p>
</details>
Easy
Not Attempted
Video
5
Same Binary Tree
Given the roots of two binary trees `p` and `q`, return `true` if the trees are **equivalent**, otherwise return `false`.
Two binary trees are considered **equivalent** if they share the exact same structure and the nodes have the same values.
**Example 1:**
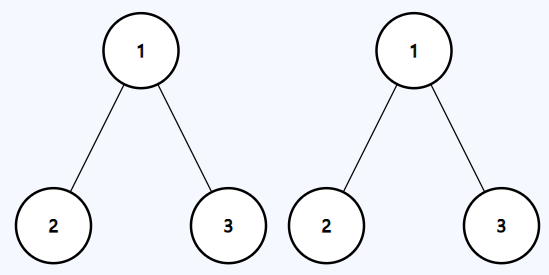
```java
Input: p = [1,2,3], q = [1,2,3]
Output: true
```
**Example 2:**
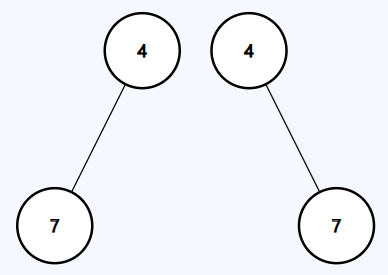
```java
Input: p = [4,7], q = [4,null,7]
Output: false
```
**Example 3:**

```java
Input: p = [1,2,3], q = [1,3,2]
Output: false
```
**Constraints:**
* `0 <= The number of nodes in both trees <= 100`.
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
Can you think of an algorithm that is used to traverse the tree? Maybe in terms of recursion.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse the tree. Can you think of a way to simultaneously traverse both the trees?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We traverse both trees starting from their root nodes. At each step in the recursion, we check if the current nodes in both trees are either <code>null</code> or have the same value. If one node is <code>null</code> while the other is not, or if their values differ, we return <code>false</code>. If the values match, we recursively check their <code>left</code> and <code>right</code> subtrees. If any recursive call returns <code>false</code>, the result for the current recursive call is <code>false</code>.
</p>
</details>
Easy
Not Attempted
Video
6
Subtree of Another Tree
Given the roots of two binary trees `root` and `subRoot`, return `true` if there is a subtree of `root` with the same structure and node values of `subRoot` and `false` otherwise.
A subtree of a binary tree `tree` is a tree that consists of a node in `tree` and all of this node's descendants. The tree `tree` could also be considered as a subtree of itself.
**Example 1:**
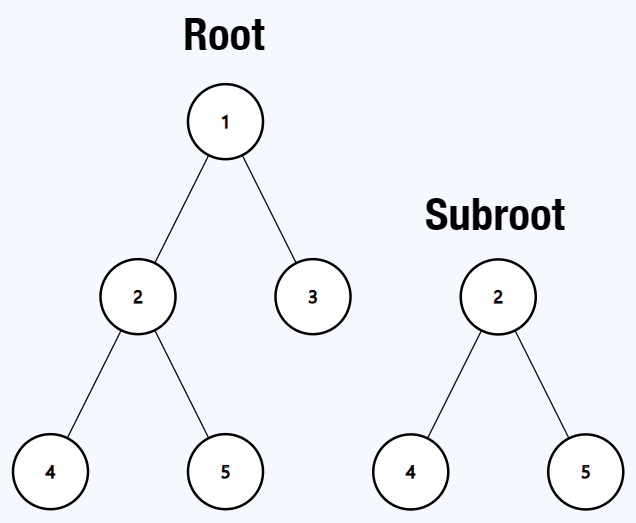
```java
Input: root = [1,2,3,4,5], subRoot = [2,4,5]
Output: true
```
**Example 2:**
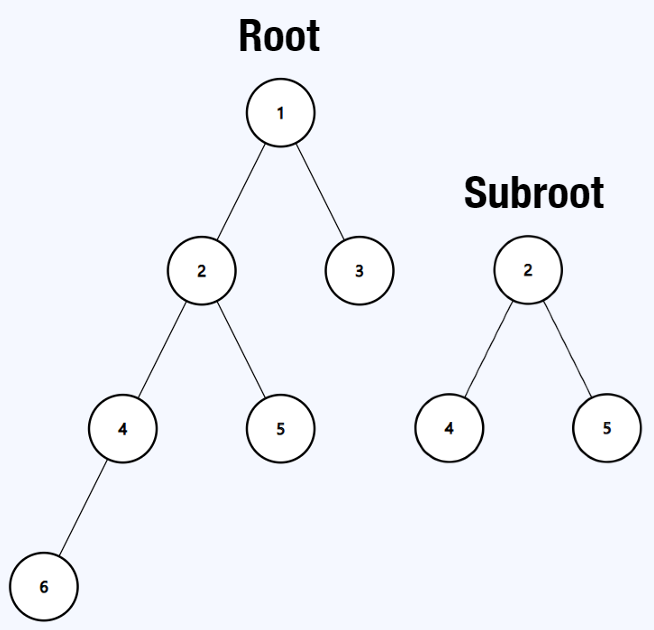
```java
Input: root = [1,2,3,4,5,null,null,6], subRoot = [2,4,5]
Output: false
```
**Constraints:**
* `1 <= The number of nodes in both trees <= 100`.
* `-100 <= root.val, subRoot.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(m * n)</code> time and <code>O(m + n)</code> space, where <code>n</code> and <code>m</code> are the number of nodes in <code>root</code> and <code>subRoot</code>, respectively.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A subtree of a tree is a tree rooted at a specific node. We need to check whether the given <code>subRoot</code> is identical to any of the subtrees of <code>root</code>. Can you think of a recursive way to check this? Maybe you can leverage the idea of solving a problem where two trees are given, and you need to check whether they are identical in structure and values.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
When two trees are identical, it means that every node in both trees has the same value and structure. We can use the Depth First Search (DFS) algorithm to solve the problem. How do you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We traverse the given <code>root</code>, and at each node, we check if the subtree rooted at that node is identical to the given <code>subRoot</code>. We use a helper function, <code>sameTree(root1, root2)</code>, to determine whether the two trees passed to it are identical in both structure and values.
</p>
</details>
Easy
Not Attempted
Video
7
Lowest Common Ancestor in Binary Search Tree
Given a binary search tree (BST) where all node values are *unique*, and two nodes from the tree `p` and `q`, return the lowest common ancestor (LCA) of the two nodes.
The lowest common ancestor between two nodes `p` and `q` is the lowest node in a tree `T` such that both `p` and `q` as descendants. The ancestor is allowed to be a descendant of itself.
**Example 1:**
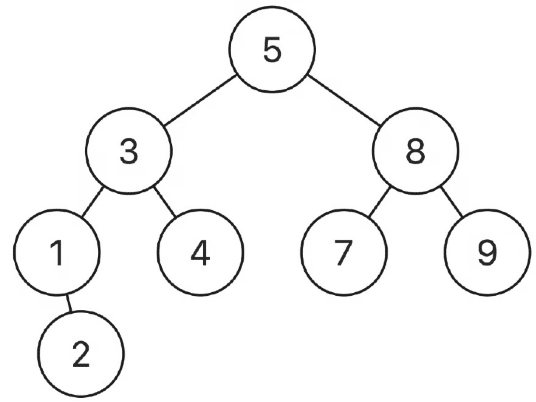
```java
Input: root = [5,3,8,1,4,7,9,null,2], p = 3, q = 8
Output: 5
```
**Example 2:**

```java
Input: root = [5,3,8,1,4,7,9,null,2], p = 3, q = 4
Output: 3
```
Explanation: The LCA of nodes 3 and 4 is 3, since a node can be a descendant of itself.
**Constraints:**
* `2 <= The number of nodes in the tree <= 100`.
* `-100 <= Node.val <= 100`
* `p != q`
* `p` and `q` will both exist in the BST.
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(h)</code> time and <code>O(h)</code> space, where <code>h</code> is the height of the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A Binary Search Tree (BST) is a tree in which the values of all nodes in the left subtree of a node are less than the node's value, and the values of all nodes in the right subtree are greater than the node's value. Additionally, every subtree of a BST must also satisfy this property, meaning the "less than" or "greater than" condition is valid for all nodes in the tree, not just the root. How can you use this idea to find the LCA of the given nodes in the tree?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use recursion to traverse the tree. Can you figure out the conditions we encounter when choosing a path between the left and right subtrees during traversal using the values of the two given nodes? Perhaps you can determine the LCA by traversing based on these conditions.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
If nodes <code>p</code> and <code>q</code> are in different subtrees, a split occurs, making the current node the LCA. If both are in the left or right subtree, the LCA lies in that subtree and we further choose that subtree to traverse using recursion. You should also handle other multiple scenarios to get the LCA.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
The LCA can also be one of the nodes, <code>p</code> or <code>q</code>, if the current node is equal to either of them. This is because if we encounter either <code>p</code> or <code>q</code> during the traversal, that node is the LCA.
</p>
</details>
Medium
Not Attempted
Video
8
Binary Tree Level Order Traversal
Given a binary tree `root`, return the level order traversal of it as a nested list, where each sublist contains the values of nodes at a particular level in the tree, from left to right.
**Example 1:**
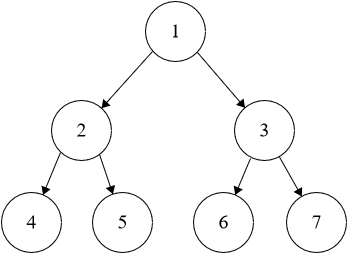
```java
Input: root = [1,2,3,4,5,6,7]
Output: [[1],[2,3],[4,5,6,7]]
```
**Example 2:**
```java
Input: root = [1]
Output: [[1]]
```
**Example 3:**
```java
Input: root = []
Output: []
```
**Constraints:**
* `0 <= The number of nodes in the tree <= 1000`.
* `-1000 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
The level of a tree refers to the nodes that are at equal distance from the root node. Can you think of an algorithm that traverses the tree level by level, rather than going deeper into the tree?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Breadth First Search (BFS) algorithm to traverse the tree level by level. BFS uses a queue data structure to achieve this. At each step of BFS, we only iterate over the queue up to its size at that step. Then, we take the left and right child pointers and add them to the queue. This allows us to explore all paths simultaneously.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
The number of times we iterate the queue corresponds to the number of levels in the tree. At each step, we pop all nodes from the queue for the current level and add them collectively to the resultant array. This ensures that we capture all nodes at each level of the tree.
</p>
</details>
Medium
Not Attempted
Video
9
Binary Tree Right Side View
You are given the `root` of a binary tree. Return only the values of the nodes that are visible from the right side of the tree, ordered from top to bottom.
**Example 1:**

```java
Input: root = [1,2,3]
Output: [1,3]
```
**Example 2:**
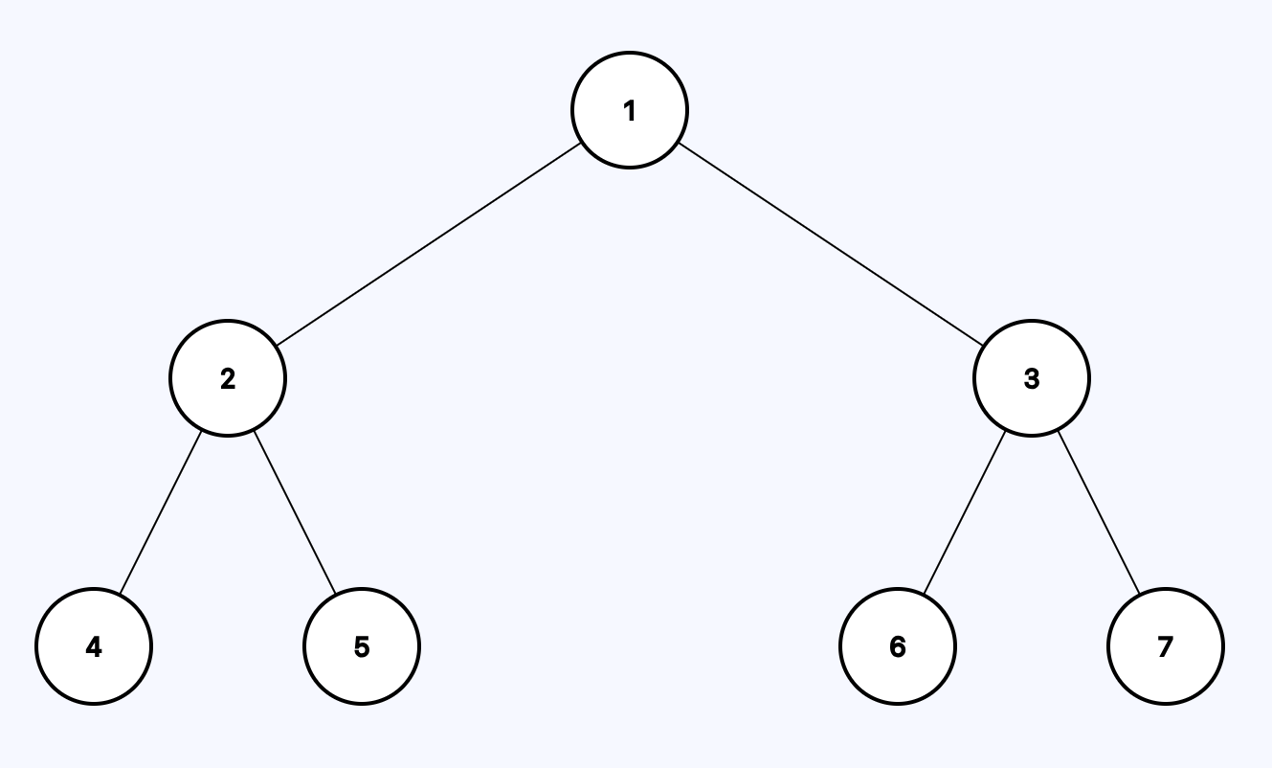
```java
Input: root = [1,2,3,4,5,6,7]
Output: [1,3,7]
```
**Constraints:**
* `0 <= number of nodes in the tree <= 100`
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
In the right-side view of a tree, can you identify the nodes that are visible? Maybe you could traverse the tree level by level and determine which nodes are visible from the right side.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
The nodes visible in the right-side view are the last nodes at each level of the tree. Can you think of an algorithm to identify these nodes? Maybe an algorithm that can traverse the tree level by level.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We can use the Breadth First Search (BFS) algorithm to traverse the tree level by level. Once we completely visit a level, we take the last node of that level and add it to the result array. After processing all levels, we return the result.
</p>
</details>
Medium
Not Attempted
Video
10
Count Good Nodes in Binary Tree
Within a binary tree, a node `x` is considered **good** if the path from the root of the tree to the node `x` contains no nodes with a value greater than the value of node `x`
Given the root of a binary tree `root`, return the number of **good** nodes within the tree.
**Example 1:**
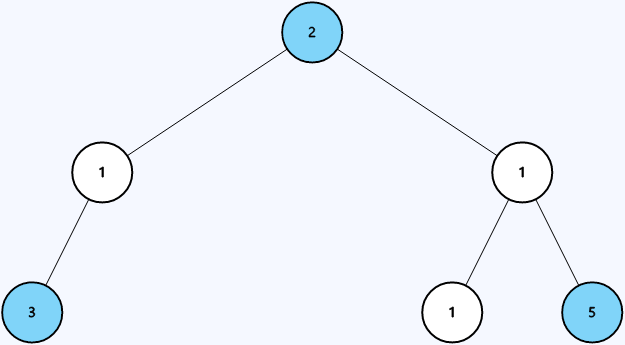
```java
Input: root = [2,1,1,3,null,1,5]
Output: 3
```
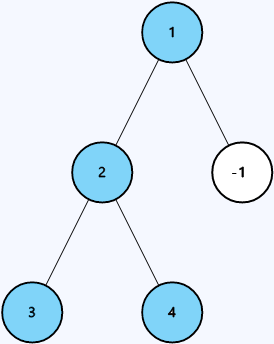
**Example 2:**
```java
Input: root = [1,2,-1,3,4]
Output: 4
```
**Constraints:**
* `1 <= number of nodes in the tree <= 100`
* `-100 <= Node.val <= 100`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and<code>O(n)</code> space, where <code>n</code> is the number of nodes in the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve considering every node and checking if the path from the root to that node is valid, resulting in an <code>O(n^2)</code> time complexity. Can you think of a better approach?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse the tree. But can you think of a way to determine if the current node is a good node in a single traversal? Maybe we need to track a value while traversing the tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
While traversing the tree, we should track the maximum value along the current path. This allows us to determine whether the nodes we encounter are good. We can use a global variable to count the number of good nodes.
</p>
</details>
Medium
Not Attempted
Video
11
Valid Binary Search Tree
Given the `root` of a binary tree, return `true` if it is a **valid binary search tree**, otherwise return `false`.
A **valid binary search tree** satisfies the following constraints:
* The left subtree of every node contains only nodes with keys **less than** the node's key.
* The right subtree of every node contains only nodes with keys **greater than** the node's key.
* Both the left and right subtrees are also binary search trees.
**Example 1:**
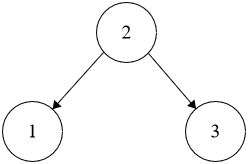
```java
Input: root = [2,1,3]
Output: true
```
**Example 2:**
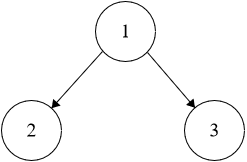
```java
Input: root = [1,2,3]
Output: false
```
Explanation: The root node's value is 1 but its left child's value is 2 which is greater than 1.
**Constraints:**
* `1 <= The number of nodes in the tree <= 1000`.
* `-1000 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve traversing the tree and, for every node, checking its entire left subtree to ensure all nodes are less than the current node, and its entire right subtree to ensure all nodes are greater. This results in an <code>O(n^2)</code> solution. Can you think of a better way? Maybe tracking values during the traversal would help.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse the tree. At each node, we need to ensure that the tree rooted at that node is a valid Binary Search Tree (BST). One way to do this is by tracking an interval that defines the lower and upper limits for the node's value in that subtree. This interval will be updated as we move down the tree, ensuring each node adheres to the BST property.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We start with the interval <code>[-infinity, infinity]</code> for the root node. As we traverse the tree, when checking the left subtree, we update the maximum value limit because all values in the left subtree must be less than the current node's value. Conversely, when checking the right subtree, we update the minimum value limit because all values in the right subtree must be greater than the current node's value.
</p>
</details>
Medium
Not Attempted
Video
12
Kth Smallest Integer in BST
Given the `root` of a binary search tree, and an integer `k`, return the `kth` smallest value (**1-indexed**) in the tree.
A **binary search tree** satisfies the following constraints:
* The left subtree of every node contains only nodes with keys **less than** the node's key.
* The right subtree of every node contains only nodes with keys **greater than** the node's key.
* Both the left and right subtrees are also binary search trees.
**Example 1:**
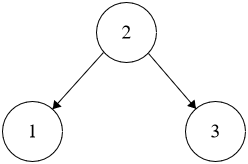
```java
Input: root = [2,1,3], k = 1
Output: 1
```
**Example 2:**
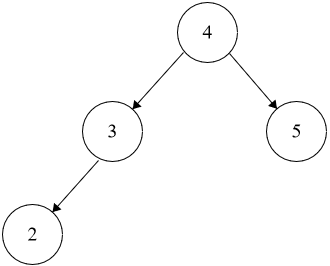
```java
Input: root = [4,3,5,2,null], k = 4
Output: 5
```
**Constraints:**
* `1 <= k <= The number of nodes in the tree <= 1000`.
* `0 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution as good or better than <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A naive solution would be to store the node values in an array, sort it, and then return the <code>k-th</code> value from the sorted array. This would be an <code>O(nlogn)</code> solution due to sorting. Can you think of a better way? Maybe you should try one of the traversal technique.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse the tree. Since the tree is a Binary Search Tree (BST), we can leverage its structure and perform an in-order traversal, where we first visit the left subtree, then the current node, and finally the right subtree. Why? Because we need the <code>k-th</code> smallest integer, and by visiting the left subtree first, we ensure that we encounter smaller nodes before the current node. How can you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We keep a counter variable <code>cnt</code> to track the position of the current node in the ascending order of values. When <code>cnt == k</code>, we store the current node's value in a global variable and return. This allows us to identify and return the <code>k-th</code> smallest element during the in-order traversal.
</p>
</details>
Medium
Not Attempted
Video
13
Construct Binary Tree from Preorder and Inorder Traversal
You are given two integer arrays `preorder` and `inorder`.
* `preorder` is the preorder traversal of a binary tree
* `inorder` is the inorder traversal of the same tree
* Both arrays are of the same size and consist of unique values.
Rebuild the binary tree from the preorder and inorder traversals and return its root.
**Example 1:**
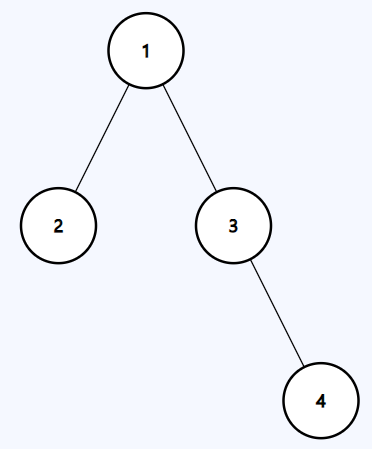
```java
Input: preorder = [1,2,3,4], inorder = [2,1,3,4]
Output: [1,2,3,null,null,null,4]
```
**Example 2:**
```java
Input: preorder = [1], inorder = [1]
Output: [1]
```
**Constraints:**
* `1 <= inorder.length <= 1000`.
* `inorder.length == preorder.length`
* `-1000 <= preorder[i], inorder[i] <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
You can observe that the in-order traversal helps divide the array into two halves based on the root node: the left part corresponds to the left subtree, and the right part corresponds to the right subtree. Can you think of how we can get the index of the root node in the in-order array? Maybe you should look into the pre-order traversal array.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
From the pre-order traversal, we know that the first node is the root node. Using this information, can you now construct the binary tree?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
After getting the root node from pre-order traversal, we then look for the index of that node in the in-order array. We can linearly search for the index but this would be an <code>O(n^2)</code> solution. Can you think of a better way? Maybe we can use a data structure to get the index of a node in <code>O(1)</code>?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We can use a hash map to get the index of any node in the in-order array in <code>O(1)</code> time. How can we implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 5</summary>
<p>
We use Depth First Search (DFS) to construct the tree. A global variable tracks the current index in the pre-order array. Indices <code>l</code> and <code>r</code> represent the segment in the in-order array for the current subtree. For each node in the pre-order array, we create a node, find its index in the in-order array using the hash map, and recursively build the left and right subtrees by splitting the range <code>[l, r]</code> into two parts for the left and right subtrees.
</p>
</details>
Medium
Not Attempted
Video
14
Binary Tree Maximum Path Sum
Given the `root` of a *non-empty* binary tree, return the maximum **path sum** of any *non-empty* path.
A **path** in a binary tree is a sequence of nodes where each pair of adjacent nodes has an edge connecting them. A node can *not* appear in the sequence more than once. The path does *not* necessarily need to include the root.
The **path sum** of a path is the sum of the node's values in the path.
**Example 1:**
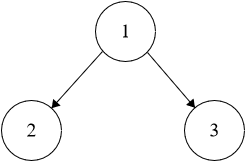
```java
Input: root = [1,2,3]
Output: 6
```
Explanation: The path is 2 -> 1 -> 3 with a sum of 2 + 1 + 3 = 6.
**Example 2:**
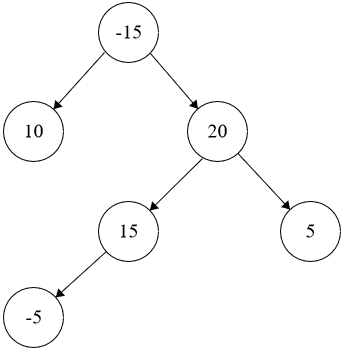
```java
Input: root = [-15,10,20,null,null,15,5,-5]
Output: 40
```
Explanation: The path is 15 -> 20 -> 5 with a sum of 15 + 20 + 5 = 40.
**Constraints:**
* `1 <= The number of nodes in the tree <= 1000`.
* `-1000 <= Node.val <= 1000`
<br>
<br>
<details class="hint-accordion">
<summary>Recommended Time & Space Complexity</summary>
<p>
You should aim for a solution with <code>O(n)</code> time and <code>O(n)</code> space, where <code>n</code> is the number of nodes in the given tree.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 1</summary>
<p>
A brute force solution would involve checking the path sum between every pair of nodes in the tree, leading to an <code>O(n^2)</code> time complexity. Can you think of a more efficient approach? Consider what information you would need at each node to calculate the path sum if it passes through the current node.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 2</summary>
<p>
At a node, there are three scenarios to compute the maximum path sum that includes the current node. One includes both the left and right subtrees, with the current node as the connecting node. Another path sum includes only one of the subtrees (either left or right), but not both. Another considers the path sum extending from the current node to the parent. However, the parent’s contribution is computed during the traversal at the parent node. Can you implement this?
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 3</summary>
<p>
We can use the Depth First Search (DFS) algorithm to traverse the tree. We maintain a global variable to track the maximum path sum. At each node, we first calculate the maximum path sum from the left and right subtrees by traversing them. After that, we compute the maximum path sum at the current node. This approach follows a post-order traversal, where we visit the subtrees before processing the current node.
</p>
</details>
<br>
<details class="hint-accordion">
<summary>Hint 4</summary>
<p>
We return the maximum path sum from the current node to its parent, considering only one of the subtrees (either left or right) to extend the path. While calculating the left and right subtree path sums, we also ensure that we take the maximum with <code>0</code> to avoid negative sums, indicating that we should not include the subtree path in the calculation of the maximum path at the current node.
</p>
</details>
Hard
Not Attempted
Video